あけましておめでとうございます!
年末年始は久しぶりに青森に帰省していたこともあり、すでに1月5日になってしまいました。
今年も恒例になりつつある、活動棚卸しと今年の方針をまとめてみたいと思います。4回目ともなると、具体性が出てきて大変良いですね。
- 2021年 振り返り
- 2022年の方針
- おわりに
あけましておめでとうございます!
年末年始は久しぶりに青森に帰省していたこともあり、すでに1月5日になってしまいました。
今年も恒例になりつつある、活動棚卸しと今年の方針をまとめてみたいと思います。4回目ともなると、具体性が出てきて大変良いですね。
LogicApps の配列フィルターのアクションをよく使うんですが、OR条件とかAND条件とか使いたくなるときがありますよね。

何度か使ってるので、書き残しておこうと思います。
通常は配列の要素を「Item()」で取り出して、判定します。
配列にオブジェクト要素が入っていれば、「Item()['ObjectName']」で取り出します。
あとは条件を書くだけ、というシンプルなものですね。
例えば、以下のような設定であれば、

こんな感じの結果になりますね。

ただ、このフィルター条件、初期のUIだと一つしか条件を記述することができません。
そこで、詳細モードが利用できます。
詳細モードの使い方は単純です。配列の要素が一つ一つ取り出されて条件にかけられるものなので、その一つ一つに対して「True」か「False」を返すだけです。
なので、equalsやcontaincsなどの論理比較関数を使って結果を返すのが通常の使い方です。
さっきと同じ条件の書き方が以下のようになります。
@equals(item(), 3)

最終的に「True」として判定されたものだけが、結果の要素として取り出すことができます。
詳細モードの使い方がわかっていれば、そんなに難しいことはありません。シンプルにand・or の関数が利用できます。
例えば、[1,2,3,4,5] の配列のうち、「3」もしくは「4」に一致する場合のみ抽出したい場合は、以下のように記述します。
@or(equals(item(), 3),equals(item(), 4))


これで、and条件も同様に記述できます。
and or をネストさせれば、さらに細かな複合条件も書けますが、あとは見渡し次第かなと思います。
関数が書きづらい、といった場合には複数のフィルターアクションを作ることでも実現できます。
以下のHiroさんのブログが参考になると思います。実現することは一緒なので、お好みのやり方でどうぞ。
LogicApps のデバッグって結構面倒ですよね。
四六時中実行しているようなフローを作成すると、時々どんな処理を得ているのか、外部からどんなデータを取得して、実行結果がどうなったのかをもう少しうまく把握したいシチュエーションがあります。
でも、LogicAppsの実行結果って成功か失敗かしか判別できず、細かな詳細を見たいときは一つ一つ実行結果を開いて確認する必要があるんですよね。
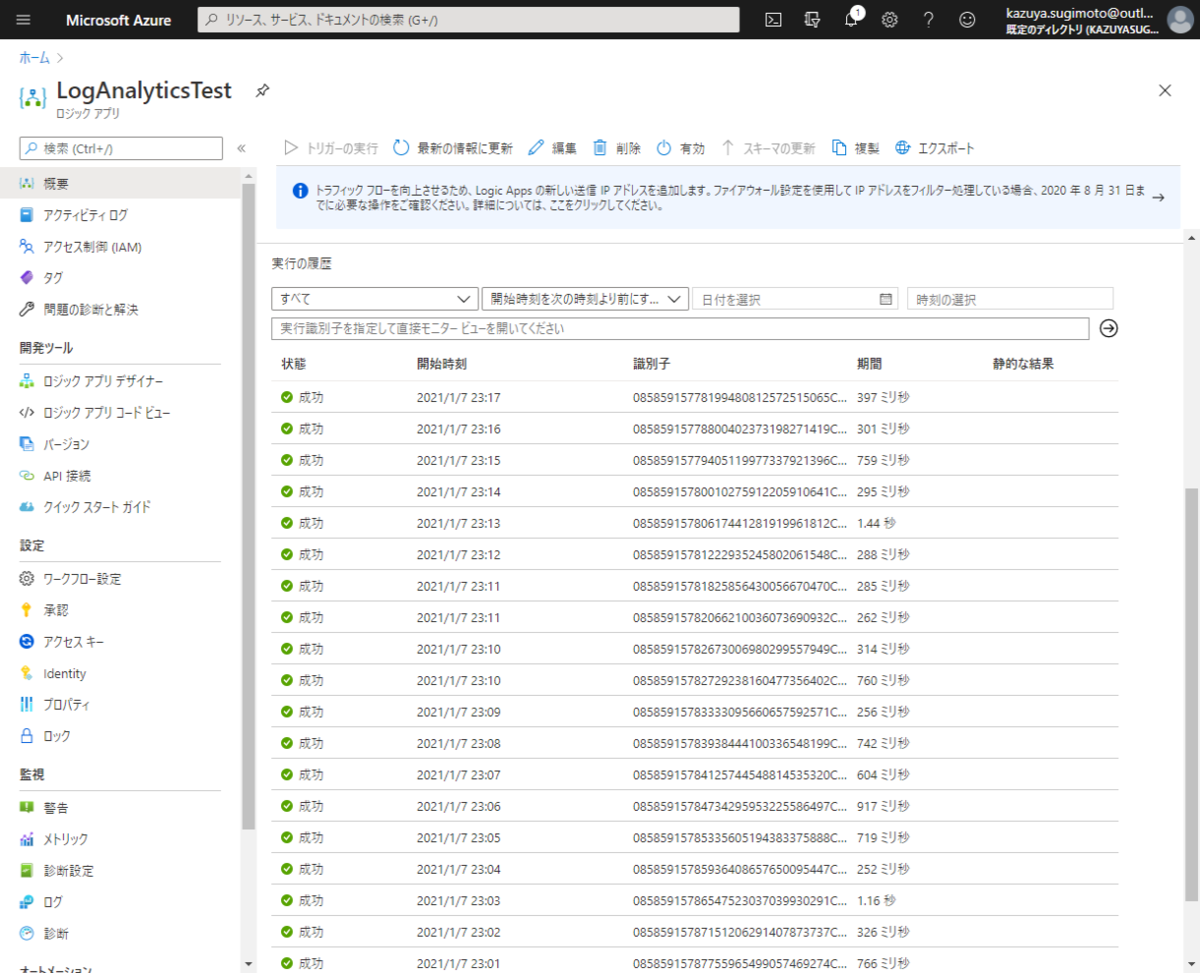
これがAzure Functionsとかなら、Azure Monitor(Log Analytics)にでもデータを出力するのに! と考えていたら、
そこで最近知った良い方法が 以下のLogicApps でのログ出力で追跡対象プロパティを設定するというものです。
これを使うことで、各アクションの実行結果もしくは入力データや固定メッセージをLog Analyticsに出力して、結果を分析しやすくなります。
この機能は予めLogicApps をLog Analyticsワークスペースと紐付けて置く必要があります。
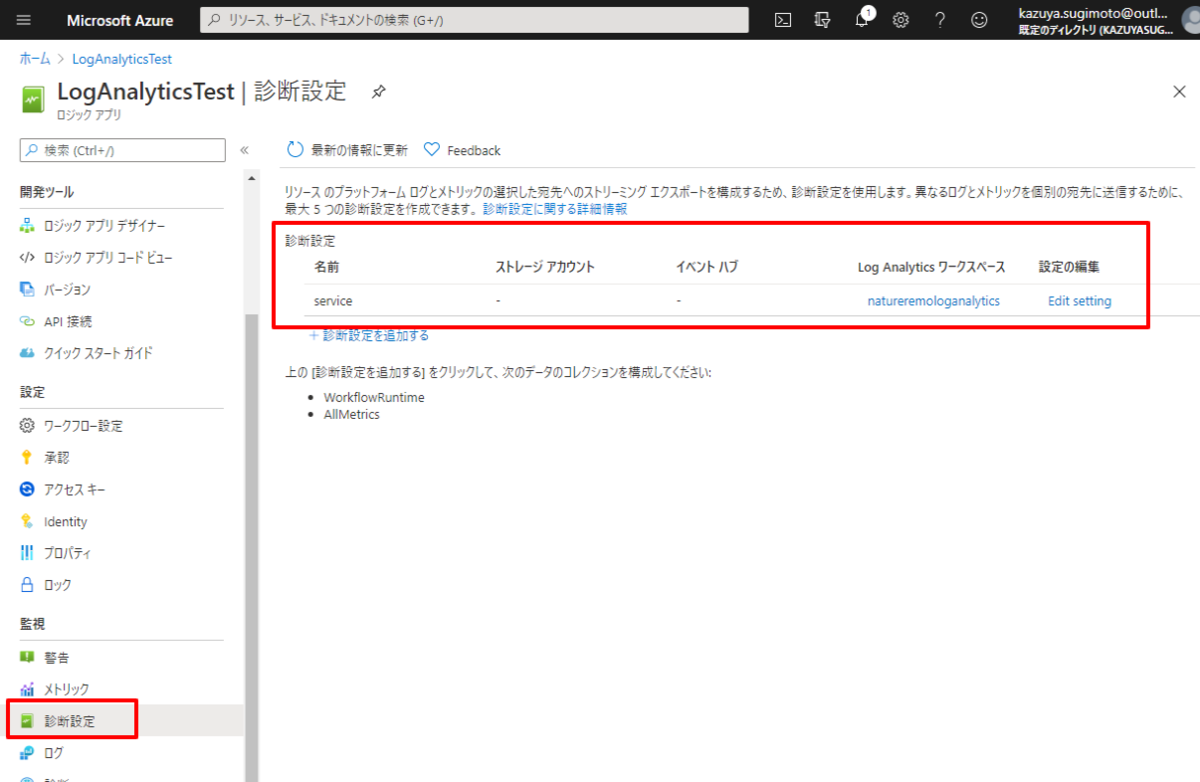
以下のWorkflowRuntimeを設定しておきましょう。
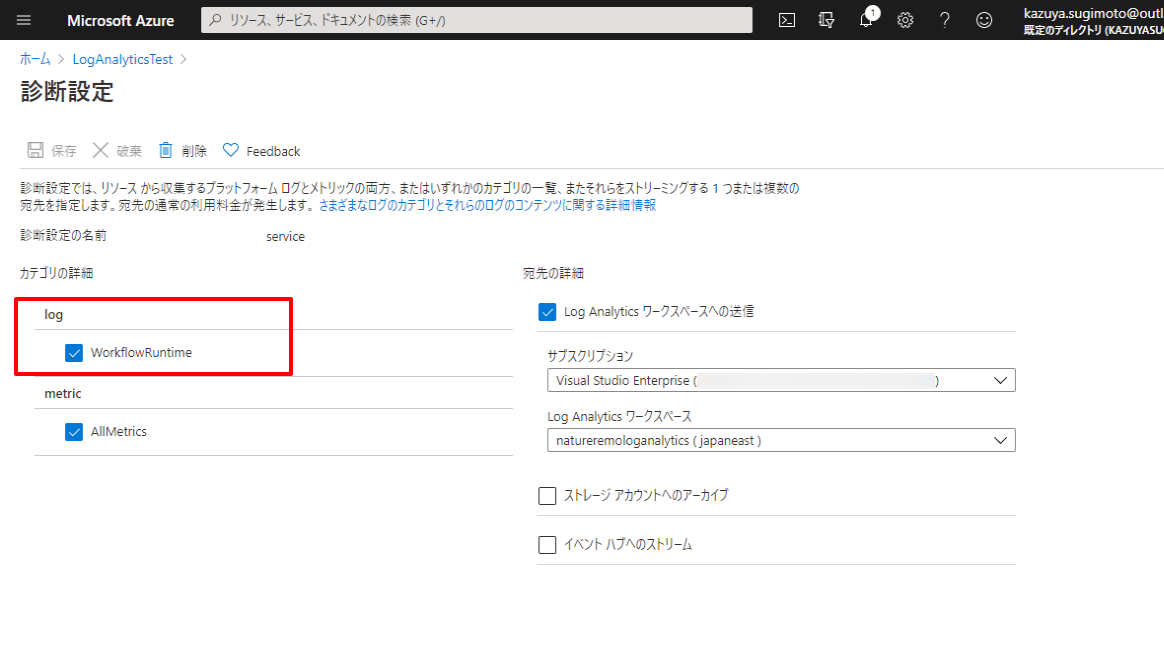
追跡対象プロパティは各アクションの「設定」から登録します。
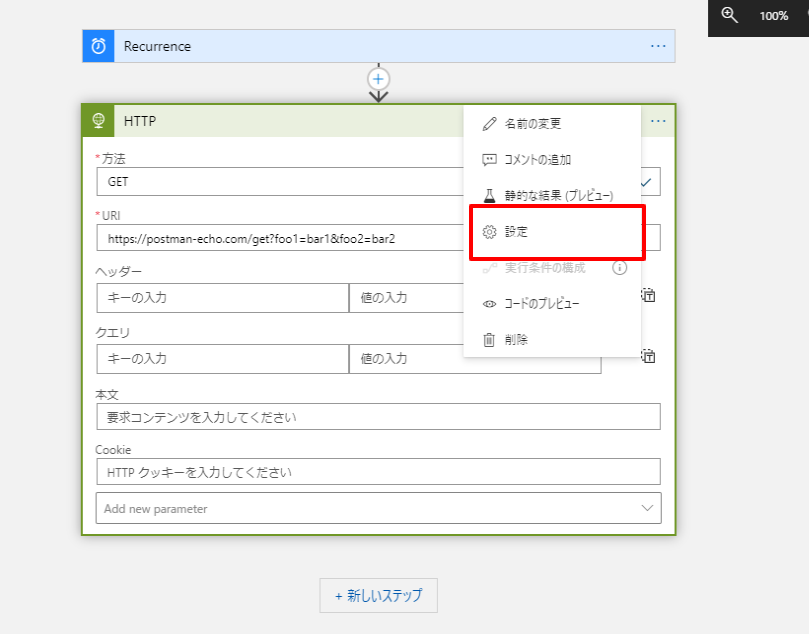
以下の部分ですね。
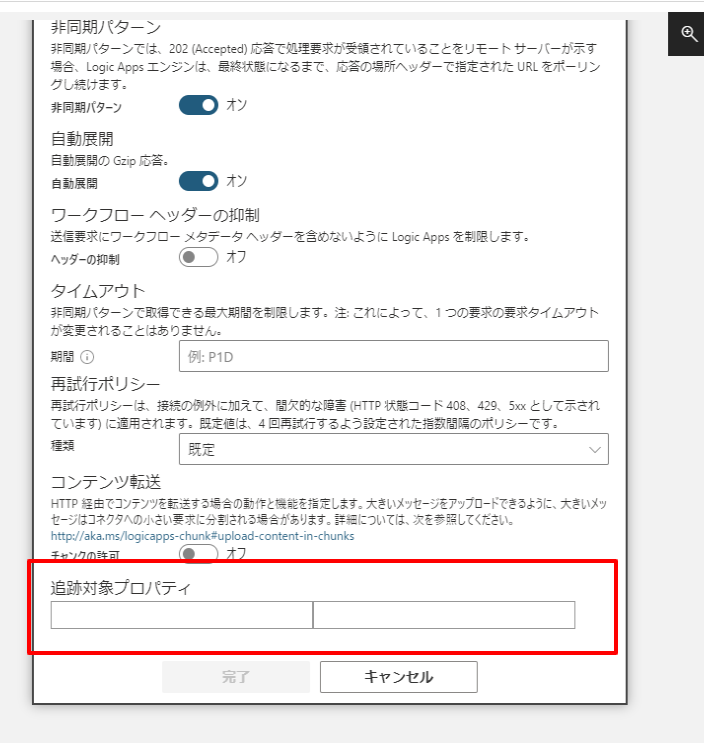
追跡対象プロパティは大きく分けて2つの設定方法があります。
一つは単純に固定メッセージを常に出力する方法です。
左側にProperty名、右側に出力メッセージを指定します。

もう一つは各関数を利用して動的に出力する方法です。
例えば対象のアクションに設定された値や出力結果の値をログに出力したい場合は「@action()」で取得できます。
「@action()」以降は入力(Inputs)と出力(Outputs)の2つのオブジェクトに別れて、
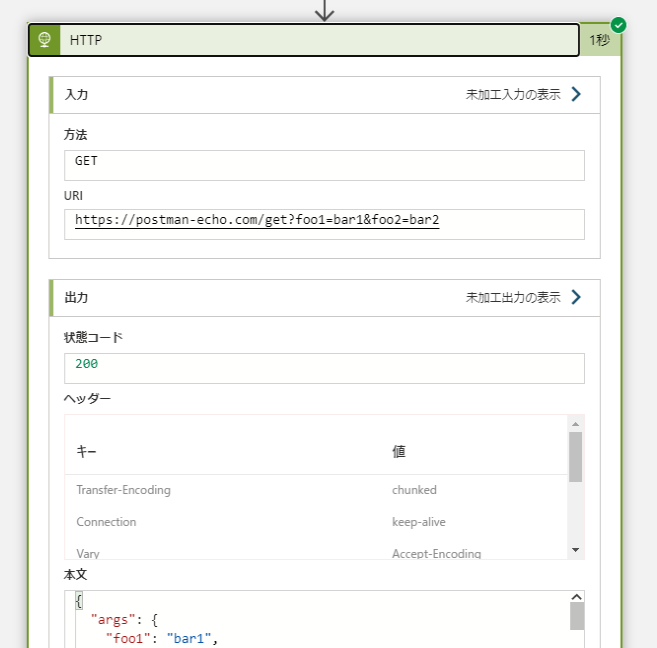
その後、それぞれのオブジェクト(未加工出力の表示)のデータにアクセスできるようになります。
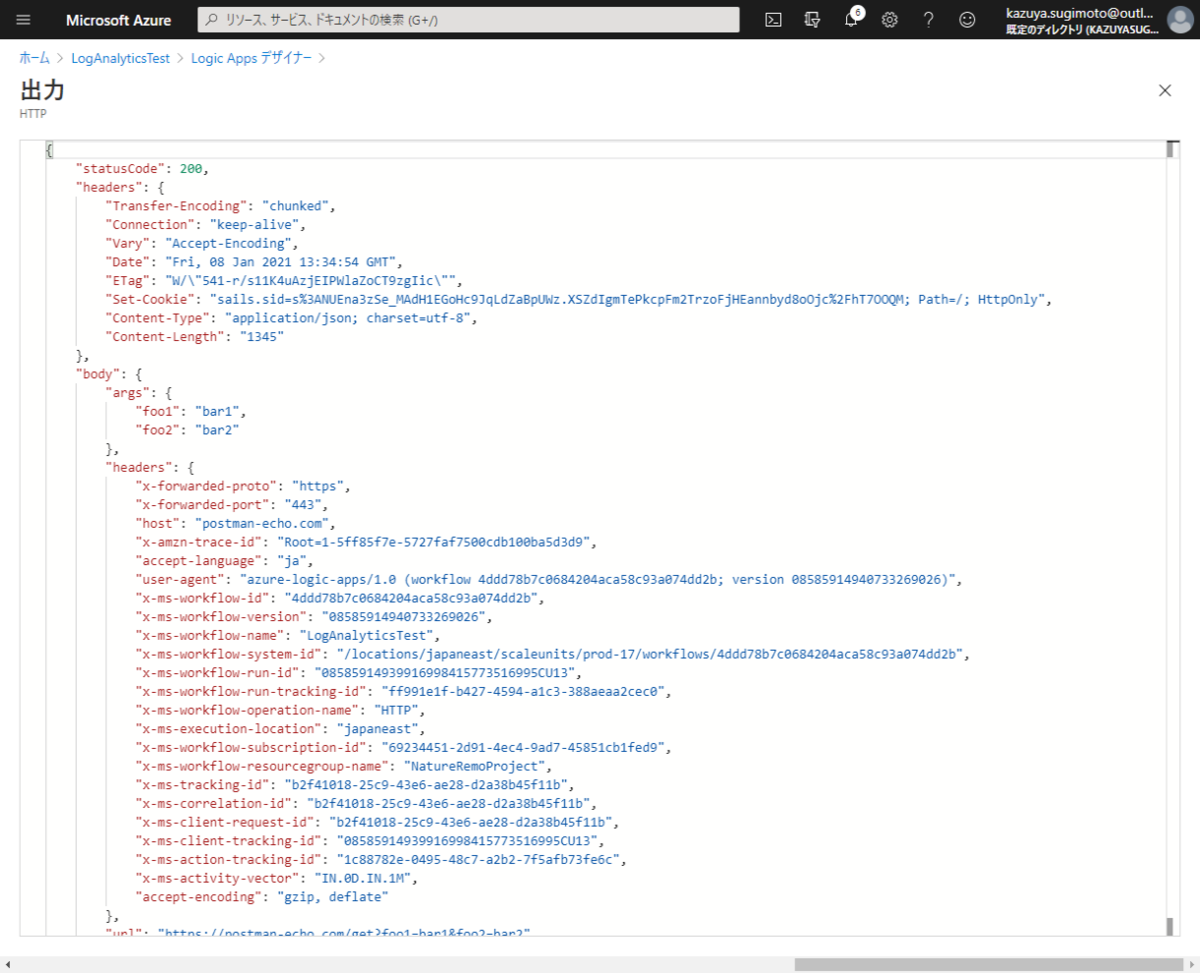
例えば、上記のHTTPアクションの出力結果のステータスコードを追跡対象プロパティとしてログに吐き出したい場合は
「@action()['outputs']['statusCode']」になりますし
「@action()['outputs']['body']['args']['foo1']」といった形でレスポンスボディにアクセスすることも可能です。

出力結果はログの「AzureDiagnostics」から確認できます。
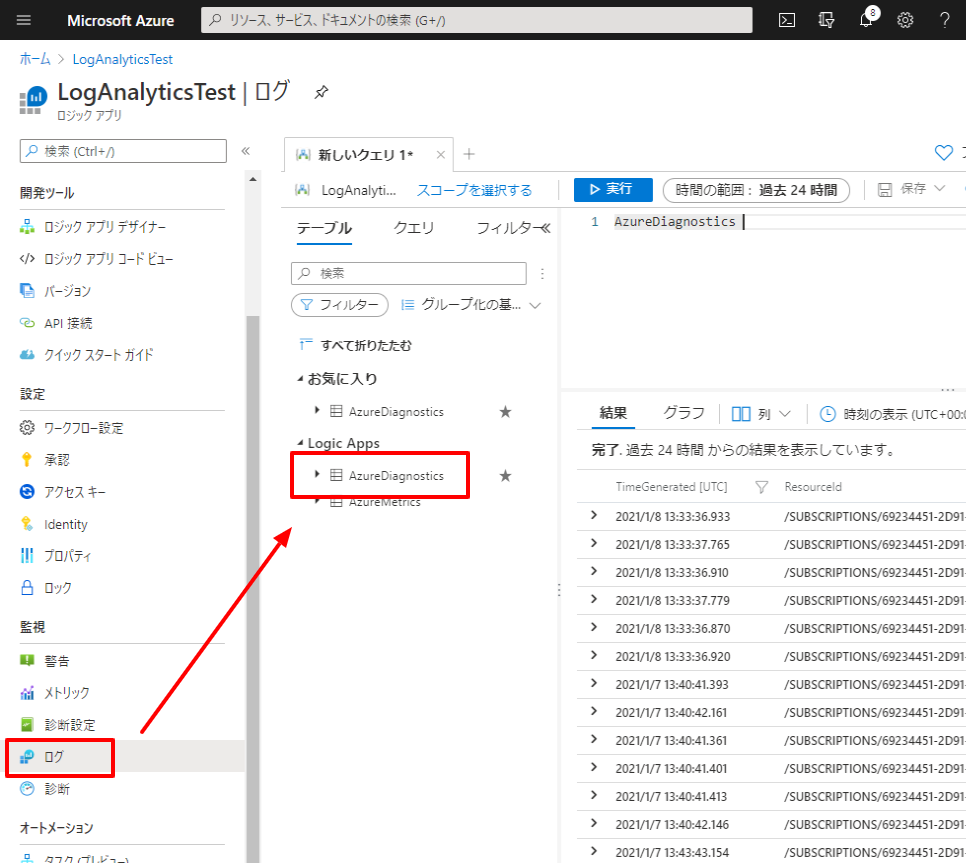
デフォルトでは項目が表示されないので「trackedProperties_XXXXX」で出力したプロパティ名を指定します。
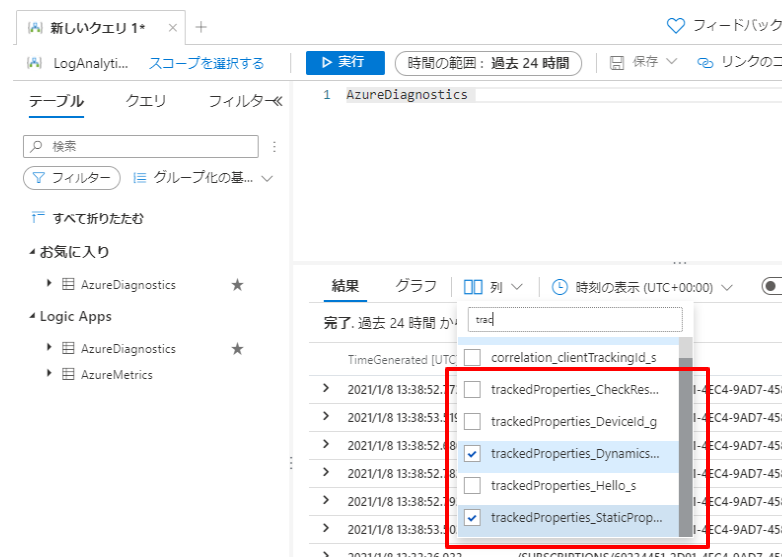
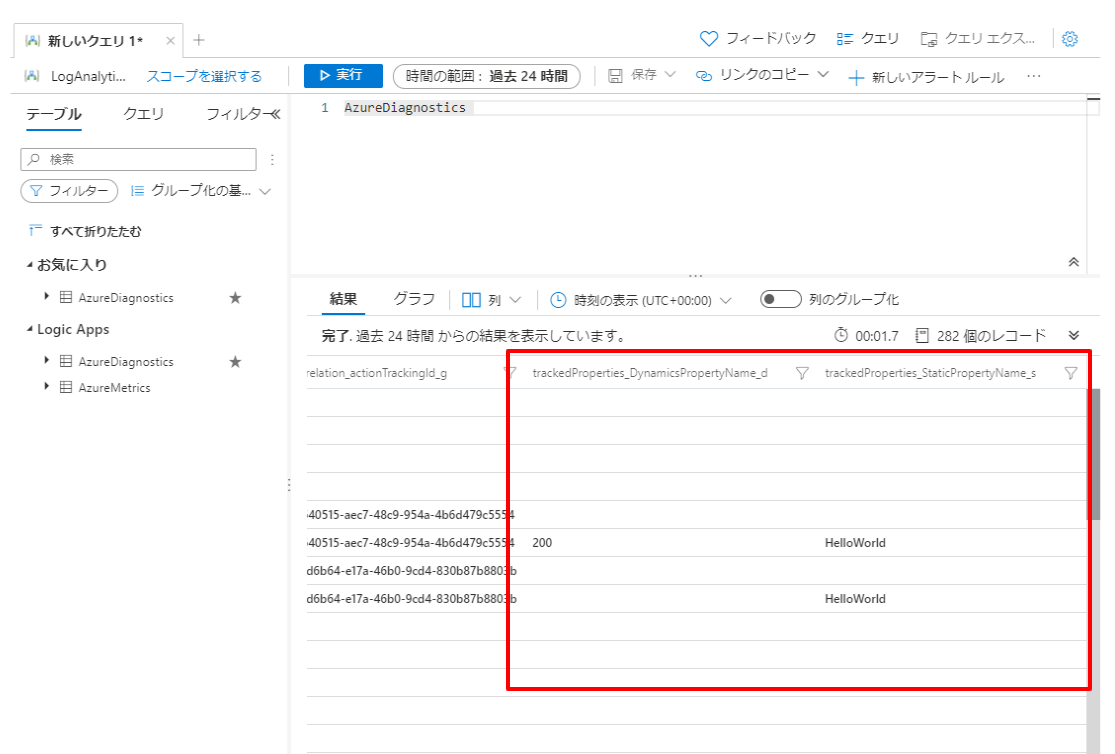
項目を表示すると、以下のように結果が出力されていることが確認できます。
あけましておめでとうございます!
去年・一昨年と継続している1年の活動の棚卸しと、2021年の方針を今年もまとめてみたいと思います。
例年通りであれば、このBlogの状況を棚卸しするのですが、2020年はこのMorning Girl Blogよりも、会社Blogにフォーカスしていました。
なので、2019年の「51件」と比べて「20件」と30件以上少ない件数になっています。
ただ、会社Blogは2019年「33件」に対して、今年は「125件」で大きく増加!初めて1年間で100件以上の記事を投稿しました。ちなみに2020年 会社Blogの全メンバー投稿数は297件だったので、40%ほどを投稿していたようです。
流石に具体的な数字は出せないですが、会社BlogのPVも前年比300%近くの増加という結果を残すことができ、とても良かったです。日々の積み重ね、継続的なコンテンツの作成はすぐには目に見えた効果は産まないですが、大事な要素ですね。
自分のBlog PVは流石に落ちました。平日であれば1日あたり700PVほどでしたが、今は500〜600ぐらいといったところです。まあしょうがないところではあります。
また2020年はBlog関連活動として、Qiita アドベントカレンダーのWeb APIカテゴリを立ち上げました。
当初はどのくらい人が集まるか不安でしたが、終わってみれば購読者数149件と全体ランキングの中でも14位となる素晴らしい結果を残すことができました!記事も多種多様なものが集まって、とてもありがたかったです。
購読者数149件、全体ランキング14位と素晴らしい反響でした!
— Kazuya Sugimoto @CData Software Japan (@sugimomoto) 2020年12月25日
API開発・API設計・API連携・SaaS API・iPaaS・AIと幅広いトピックで構成されていて、個人的にとても興味深く拝見させてもらいました!
思い切って作ってみて良かったです!https://t.co/4JF9z4zvjh pic.twitter.com/92im0wGcOo
ちなみに、2020年に書いたBlogの中で人気だった記事は以下の4つです。
Horizontal SaaS APIの調査は個人的に最も力を入れた記事であり、調査だったので、はてなブックマーク・Twitterそれぞれでとても良い評判をいただけたのが良かったですね!
なぜそのAPIは使われないのか? といったコラム記事も想定より良い評判・アクセス数があってよかったです。
SNSはほぼTwitterに絞った感じになりました。継続的に続けているのはAPIに関する投稿ですね。主に各社のAPI関連プレスリリースの取り上げや触ってみたAPIなどに関してツイートしました。
ちなみに、API関連のツイート数は12月16日時点で1453件、およそ1500件ほどAPI!API!とツイートしていたようでした。去年が1165件ほどだったので、なかなか良い具合に伸びていたようです。
今年のツイートデータを振り返ってみたところ、12月6日まで時点で1453件 APIに関するつぶやきを行っていたみたいです。
— Kazuya Sugimoto @CData Software Japan (@sugimomoto) 2020年12月24日
一日あたりだいたい4件は API! API!と呟いていたんですね。意外と少ない。 pic.twitter.com/xwY1ZzviU9
もともと2020年は1500件を目標にしていたので、あまり意識していなかったのですが、結果的に達成することができました。
それに、ずっとやりたかったAPI関連ニュースのまとめも、このTwitterのAPI投稿をまとめることで、実現することができました。
Blogをがんばった分、コミュニティやイベント関連での登壇は控えめとなり、 2019年は19のイベントで登壇を行っていましたが、2020年は5件ととても少なくなりました。
それとコロナで各種イベントには参加しやすくなったものの、どちらかと言えば家庭優先を心がけたので、通常参加もそこまでしませんでした。
主な登壇イベントは以下の通り。
lets-go-study-meeting.connpass.com
ただ、お仕事関連で登壇することがいくつかあってそれはとても良い経験となりました。社外とのコラボレーションが広がっていますね。
【9月2日開催】【API連携によるDX革命】チャットボットと200種類以上のデータを連携し業務自動化を実現するTechウェビナー https://t.co/3ywlsec0Vk
— Kazuya Sugimoto @CData Software Japan (@sugimomoto) 2020年9月2日
今日はPEPさん、LINE WORKSさんと一緒にAPIを語り尽くすウェビナーです!
途中参加もOKみたいなので、お時間ある方は是非!#API連携によるDX革命
また、登壇そのものは少なかったのですが、Blog記事・スライド・API検証などとの組み合わせでしっかりと相乗効果を狙い打ち出せたのも良い傾向でした。(ビジネス面もしかり)
個人的には勉強会に向けて準備するのではなく、結果的に勉強会で出せるだけのネタがすでにBlogなりで用意されているというのが理想です。そこにいくつかの取り組みでは近づけたかなと。
2020年も数多くのAPIを検証しました。API仕様書を見た数であれば、Horizontal SaaS APIの調査レポートのおかげで、300件近くに登ります。
ちなみに、2019年のPostman Collectionの数は49件で、現在のPostman Collectionを数えてみたところ、138件 となっていました。
そのことから、2020年で実際に手を動かして検証したAPIは89件ほどだったようです。(若干重複しているものもありますが)
CData Driverと組み合わせたものは60件ほどでしょうか。正式にリリースしたものは以下のプレスリリースでも取り上げてもらっています。
この取り組みはAPI検証からDriver化、そして提供企業へのコンタクト、マーケティング協業の調整とほとんど担当していたので、良い経験となりました。その中でAPI提供企業の課題感、難しさみたいなものも垣間見えたのが興味深かったです。
また、個人的な取り組みとしては、各SaaS APIのエコシステムの促進を外部から働きかけてみようということをやっていました。
例えば、以前からもやっていた APIの使い方・ファーストステップ記事は今年も色々と書きました。
非公式の Postman Collection を作って公開するといったこともしていました。
Tesla API に関しては、PowerAutomete・LogicAppsなどで利用可能なカスタムコネクターも公開してみました。
直接的にビジネスに繋がるというわけではないですが、APIカルチャー・ビジネス全体の隆盛につながればいいなと思い、引き続き取り組んでいきたいところです。
今までもちまちま英語の勉強はしていたんですが、2020年は継続的に英語学習に取り組むことができました。
特に今年前半に購入した iPad Air が大活躍! 文字を書くのが苦手な私にとって、タイピングは自分の理解力促進と記憶への定着のために重要な要素なのですが、iPad Air とキーボードは最良のツールでした。
このおかげで、毎朝20〜30分ほど、アプリで継続的に学習する習慣が身について、1年間ほぼ毎日取り組むことができました。
アプリは最初に「Duolingo 」で基礎的な部分を網羅。
ただ、10月ぐらいですべての科目をコンプリートしたので、現在はiKnowに切り替えています。iKnow はとにかく Sentence Trainer の歯ごたえがあって、いい感じです。例文も幅広いのがいいですね。
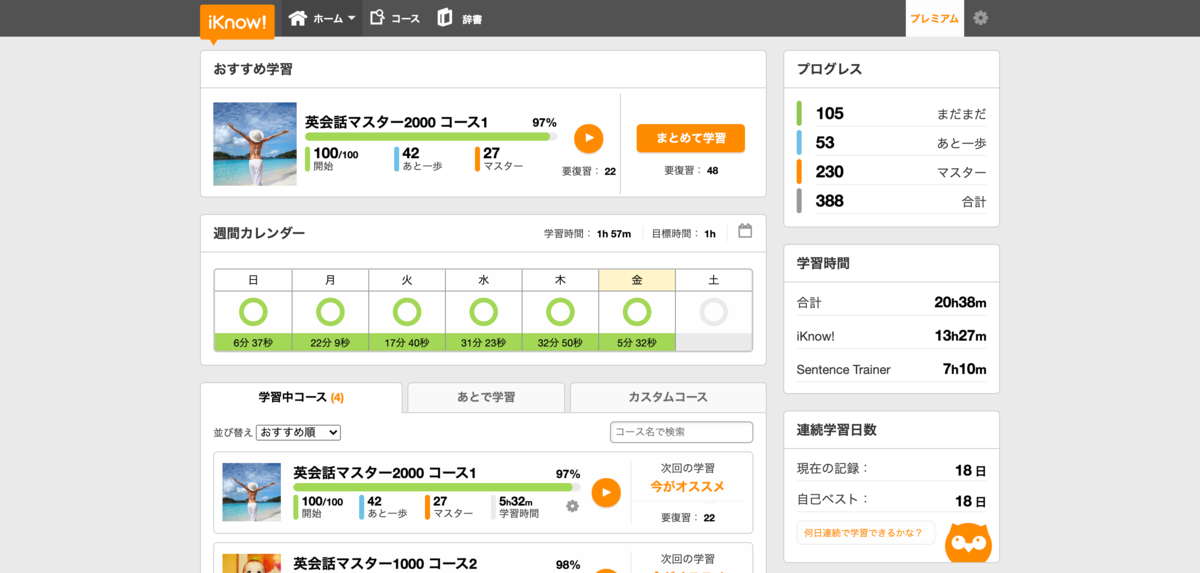
途中、Eigooo! という英語教師の方々とチャットでコミュニケーションを取りながら、学習できるサービスも試したんですが、講師の固定ができず、コミュニケーションの取り直しが発生してしまうのが面倒で1ヶ月でやめました。
以前少しやっていたスタディサプリはタイピング問題が無い感じなので、保留中。iPadにアプリ対応していないので、やめておきましたが、今調べたらブラウザからも行ける感じ? もしかしたら、2021年はやるかもしれないですね。
英語と合わせて、今年大きく力を入れて、成果を発揮したのが健康面でした。
IT関係の仕事をはじめてからというもの、頭痛・肩こりは年々ひどくなり、2019年は腰痛も出てきて、月に2,3回はゲロゲロ状態になり平日だと仕事にならないこともままありました。
また、2018年・2019年は出張も多かったので、体重もどんどん増えて、90キロの大台に・・・。2016年ごろは75キロだったので、恐ろしい増加ですね・・・。
というわけで、運動をはじめました。ただ激しい運動は継続できない、目標を立てて計画的に取り組むのは苦手、食事制限なんてしたくないし無理やり抑え込むとストレスが溜まる、という怠け者極まりない人間なので、今年はとにかく痩せようとか、筋肉をつけようとか、そんなことの前に、運動習慣を付けようということだけにフォーカスしました。
とりあえず最初にとっかかりとして始めたのは、ヨガ。近くでプライベートレッスンをやってくれるところがあったのと、空中ヨガって面白そう、ネタになりそう、という安易な考えではじめましたが、結果的にこれが一番良かったです。
1週間に1回ペースではありましたが、プライベートだったので自分の低レベルに合わせて内容を調整してくれたのがとても良かったですね。途中コロナウイルスの影響で現地からOnlineベースに移行しましたが、1年間無事継続することができました。
それと、5月の一時給付金でフィットネスバイクを買ったんですが、これがめちゃくちゃ良かったです。
家から出るのが億劫なインドア派人間であり、さらにコロナの影響でWFHな自分にとって、自宅で手軽に開始できる有酸素運動器具は、体を動かし始めるための第1ステップとしてめちゃくちゃ機能しました。買ったばかりのiPad Airを載せて、動画を見ながらできるのも大変良いですね。
これでヨガと合わせて最終的に体重は10キロ減。肩こり・腰痛・頭痛も驚くほど改善しました!
2020年は140件ほどの投稿だったので、200件くらい投稿できればいいなと思っています。
こちらも引き続き会社のBlogがメインになるとは思いますが、個人的に取り組んでいるTesla API連携プロジェクトなどは個人活動としてこっちのBlogで公開していく感じかなと思います。
また、どうしても会社の製品連携が中心になってしまいますが、最近APIそのもののアップデート・変更トピックもしっかり追っているので、APIの基本的な使い方のみならず、そういった細かなアップデートトピックも捉えながら、書いていきたいところです。
引き続きAPIに関する投稿は続けていきますが、もう少し海外のAPI News・Topicも取り上げていきたいところです。
現在 Google Alert と はてなブックマークを活用して情報収集していますが、アンテナの貼り方を変えようかなと考えています。
Google Alertを見る習慣ができているので、そこにうまく外部ソースも交えていきたいところ。ここは仕組みづくりから考えていきたいところですね。
API関連ツイート・1500というのは悪くない数字だと思っていますが、単純に数値目標を上げるというよりは、仕組み・アンテナ作りで改良を重ねたいかなというところ。それで結果的に2000いけば良いかなと思っています。
2020年は初めから絞っていこう、と思って結果的に絞った感じでした。今年もどちらかと言えばコンテンツファースト精神で、Blogや発表に耐えるネタを日々作りつつ、発表できる場があれば、そこに乗っていくという方針かなと思っています。
とはいえ、10件くらいが目標でしょうか。
2021年も引き続きAPI検証・トライアルは活発にやっていきたいところですが、方向性としてはもう少しAPI開発・マイクロサービス側・認証周りにも舵を取りたいなと思ったりです。
今までの方向性としてどちらかと言えば、すでに公開されているAPIの「活用」を主眼に置いていたので、「開発」の部分にも力を入れたいところ。
また、何かしらAPIエコシステムに寄与できるコンテンツ(SDK・Postman Collection・コネクタ)も引き続き追加できればなと。
Tesla API は引き続き色々と実験していきたいですね。
iKnowを継続してやっていく予定ですが、徐々にオンライン英会話も交えていこうかなと考えています。あと今年は英語Blogのアウトプットにも取り組んでみたいところですね。
あと今まであまりにもレベルが違うと思って、試してなかったTOIECにも一度は挑戦してみたいなと思っています。(私のレベルからすると英検からでもいいくらい)
ヨガは今年も継続したいなーと思いつつ、筋力アップにも少しづつ力を入れていきたいところ。体重は75キロとかになると嬉しいですが、まああまり気負いはせずに、今年同様1年間運動習慣を継続できればそれで良いです。
あとなんか特に大きな理由は無いんですが、逆立ちができるようになりたいなと思っています。

先日開催された .NET ラボで Tesla APIのセッションを行ったのですが、その中で Tesla API のデータをリアルタイムで分析するセッションが好評でした!
以下のツイートでも動画を公開しています。
取れた取れた!
— Kazuya Sugimoto @CData Software Japan (@sugimomoto) 2020年11月25日
Tesla API からLogicAppsを使って1秒間隔でデータを取得して、PowerBI のストリーミングデータセットに流し込み。
スピードの単位はマイルかな?
Powerという値も取ってるんだけど、イマイチなんなのかわからぬ。 pic.twitter.com/fAJkdVXFzI
内部的には Azure のローコードサービス・iPaaS である LogicAppsと BIツール・Power BI を利用しているので、特に難しい処理は意識せず実現できるようになっています。
というわけで、この記事ではその作り方を紹介します!
ちなみに Web API アドベントカレンダー1日目の記事です!
続きを読む先日公開した Tesla API の Postman Collection に続いて、今度は Microsoft PowerApps/PowerAutomate/LogicApps 用のカスタムコネクタを公開しました!
これでローコード・iPaaSでも、Tesla APIを存分に楽しめます!
使い方は簡単です。Githubで公開しているので、カスタムコネクタ画面の「URLからOpenAPIをインポートします」で、取り込むことが可能です。

任意の名称を入力し、以下のURLを貼り付けて、インポートしてください。
https://raw.githubusercontent.com/sugimomoto/TeslaAPICustomConnector/main/TeslaAPICustomConnector.json

あとは、お好みのアイコンを設定すればOKです。

セキュリティや

定義情報をいじる必要は特にありません。「コネクタの作成」をクリックして、登録できます。

認証方法はAccess TokenをAuthorizationヘッダーに指定する方式を採用しています。
小難しいことを言うと、Tesla APIはOAuth 2.0のPassword Grantを使用しているので、Access Tokenの取得は任せることができません。(頑張ればできなくもないですが)
なので、Access Tokenは前回の記事 を参考に手動で取得しておきましょう。
取得後、「新しい接続」を開き

APIキーの項目に取得したAccess TokenをBearer込みで指定します。
Access Token が「qts-12345」なら「Bearer qts-12345」と、頭にBearerをつけて入力してください。

あとは任意のアクションを実行できます。一番最初はVehiclesなどで、車両IDを特定するのが良いでしょう。

なお、Access Tokenは45日間有効です。
このカスタムコネクタを使って、毎日テスラのデータ収集と、バッテリーの使用状況の可視化を行ってます。

私は自宅に充電設備が無いので、どのくらいバッテリーを日々消費しているか可視化するのは、次の充電タイミングの予測のためにもとても便利です!

全部のエンドポイントをカスタムコネクタで叩いてみたわけではないので、色々と調整が必要な部分もあると思います。
何かあれば、GithubのIssueまで連絡ください。
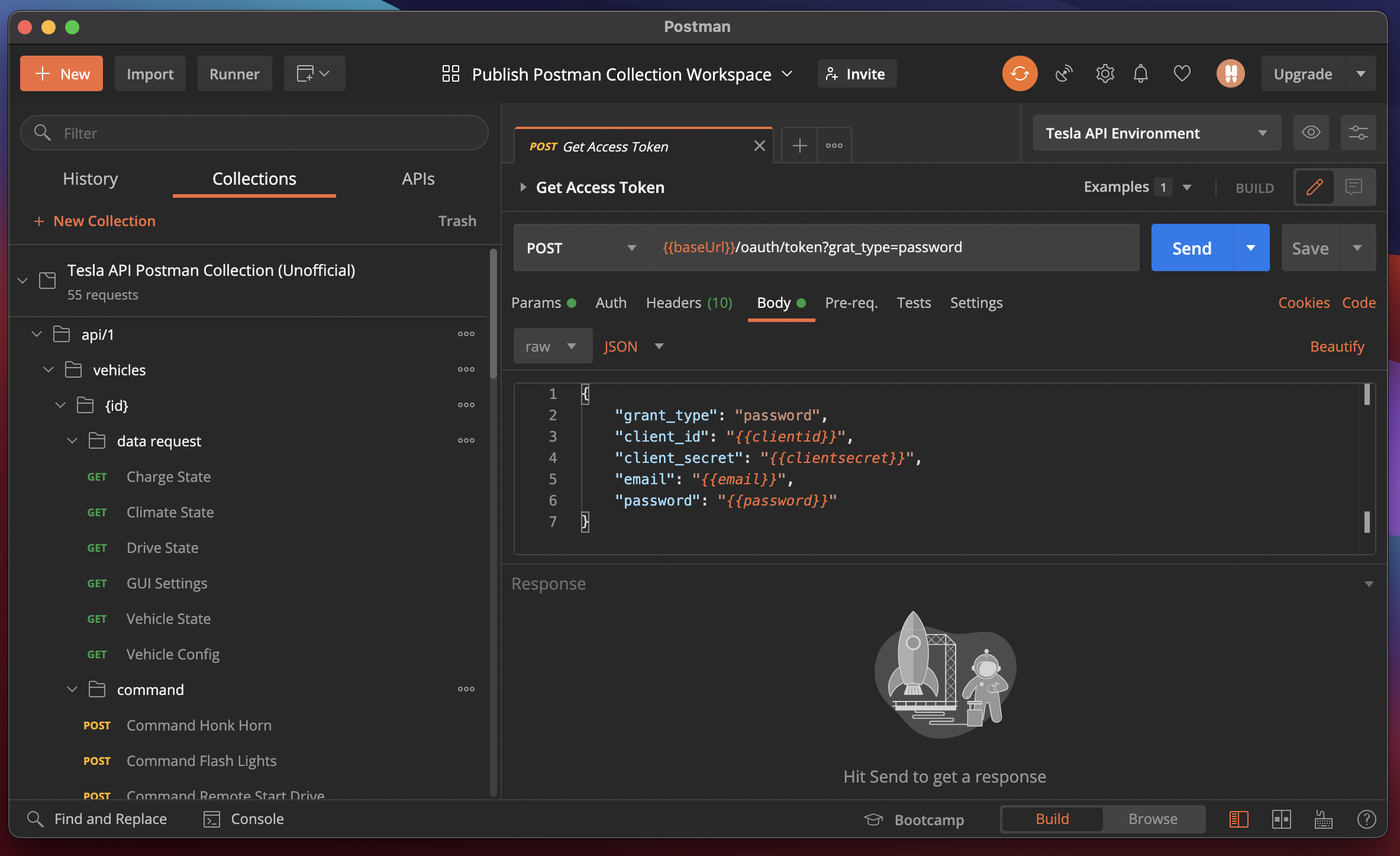
前回の記事 でTesla APIの使い方について解説したんですが、実は内部ではせっせと Open API Specを書いていまして、それを元に Postman Collectionを作ったので、公開してみました。
通常のOpen APIをインポートして使うよりも、若干設定をいじってあるので、使いやすいと思いますl。
Open API ももうちょっと綺麗にしたら公開予定。
Githubにも使い方を書いていますが、英語なのでこちらでは日本語で。
