500万件を超えるTwitter のリツイート データを取得・分析する方法 -Twitter Premium Search API を実際に使ってみてわかった嵌りポイントとその対策-
このBlogでも告知していましたが、今週の月曜日1月28日に日本マイクロソフト品川本社セミナールームC+D で「ZOZO 前澤社長のお年玉リツイート企画は、どのくらい世の中に影響を与えたのか?」を開催しました!
開催前はこんな色物企画に本当に人が来てくれるのだろうか? とずっと半信半疑でしたが、最終的に申込みは4営業日ほどで満席(108席)になりまして、イベント当日もたくさんのツイート、ご質問をいただけて、個人的にとても得るものも多く、楽しいイベントとなりました!
以下のまとめでどんな雰囲気だったか垣間見ることができるのではないかなと思います。
ただ、私自身がやったことは、このイベントのタイトルから見えるよりも、ひたすら地味なもので、Twitter API の「制約」・「制限」・「仕様」をどのように回避・咀嚼しながら、対象の500万リツイートデータ取得と分析に挑むのか? といったものでした。
もちろん、取得してきたデータから見えてきたことも最後のほうで紹介したいと思いますが、この記事としては今後 Twitter 上でキャンペーンなどを展開していく企業やユーザーの役に立ってもらえればという考えで書いています。
こんな色物な取り組みですが、是非いろいろと参考にしてもらえると幸いです。
なお、さっくりと見たい方にはほぼ同じ内容のスライドも公開しています。
ZOZO前澤社長お年玉リツイート企画のビッグデータに立ち向かう方法 -Twitterのビッグデータを分析するために、実際にやってみてわかった嵌りポイントとその対策- from Kazuya Sugimoto
www.slideshare.net
- なんでこんなことをしようと思ったのか?
- 立ちはだかる「嵌りどころ・落とし穴」たち
- 1.どうやって500万件のリツイート(+アルファ)を取得するの?
- 2.どうやって対象のツイートを識別するの?
- ボトルネック③ どうやって Twitter の JSON データを構造化するの?
- ボトルネック④ どうやって DB にデータを流し込むの?
- 終わりに
なんでこんなことをしようと思ったのか?
先のBlogでもちらっと触れたのですが、今回の企画で気になるのは対象100名の決定方法でした!
いろんな憶測ツイートでも出ている通り、標準のTwitterの機能だと結構制限が厳しいです。
Twitter 上でも

API で取得できない、件数さばけない! という声が多数!
でもそれって

ほんと・・・?
CData Software Japan という、100種類超の API を扱う会社に勤めていて、日々APIと戯れる API 中毒な人間として、黙ってられない!

いっちょやったるか、と。
それにこんな面白そうなビッグデータ、なかなか無いのではないか?
せっかくなので、このデータを分析してみたい! どんなユーザーがリツイートしているのか知りたい! ボットはどのくらい居そう? リツイートの影響数はどのくらい? この企画の期間中にツイッターアカウントを作成した人はどのくらい?
そんな疑問を解き明かすべく、どうやってTwitter データを取得したらいいのか? どうやれば、BIツールで分析できる状態になるのか? 分析するまでのアプローチ・対応方法・APIの仕様や制約をまとめてみました!
立ちはだかる「嵌りどころ・落とし穴」たち
さて、はじめたはいいものの、実際に500万件のデータを扱ったこともなければ、Twitterで取得したことも無いわけで、最終的に分析できる状況まで持っていくために、様々な困難がありました。(APIそのものは触ったことはありました)
課題は大きく分けて、4つ。この4つが実際に分析するまでの過程で遭遇した課題となっていて、これらの解決アプローチをベースにこのBlogでは解説していきます。

1.どうやって500万件のリツイート(+アルファ)を取得するの?
さて、まずまじめに取得する方法を探りますが、本題に入る前に前提条件から。
仮に ZOZO前澤社長が本気で API を使って抽選しようとした場合どうなるか?
まず気になるのがここでした。「ZOZO前澤社長が本気で API を使って抽選しようとした場合どうなるか?」
今回のイベント期間が「1月5日 22:35 ~ 1月7日 24:00」
そして当選者発表が 「1月8日 9:00」
もし、適切に当選者を全部取得して抽選するのであれば、「約50時間(24時間 ☓ 2 + 9時間)」で500万リツイート取得する必要があった、というわけですね!
それと、通常通り Twitter API を使って取得した場合どうなるの?
Standard Search の仕様としては、15分 / 180 リクエスト制限かつ、過去7日間しか遡れないという制約があります。それを元に計算してみた結果がこちら。


「間に合わない!」
のっけっから障害ですが、これにはある程度算段がありました。
2017年に発表された 有償の Search API 「Premium Search API」「Enterprise Search API」が使えるのではないか? と。
これならもっとスムーズに取得できるのではないか?
というわけで、リファレンスをみながら、「Standard Search API」「Premium Search API」「Enterprise Search API」を比較してみると・・・

いける!!! 「Premium Search API」なら、500万件取得に「2.75時間」
Enterprise Search API ならお値段はわからないけど、30分で1000万件取得できる!?
というわけで、今回はこの「Premium Search API」を使うことにしました。
なお、Premium Search AP のお値段はこちら。

ちなみに、上記エンドポイント以外に、過去の全ツイートを検索する Archive Search API がありますが、パフォーマンスは変わらないため除外しています。
2.どうやって対象のツイートを識別するの?
Premium API を使うことは決まりました。しかし、次は対象となるツイートをどう抽出するかです。
そもそも何を取得したかったのか?
これに関しては、もちろん、以下のリツイートが対象ではありますが
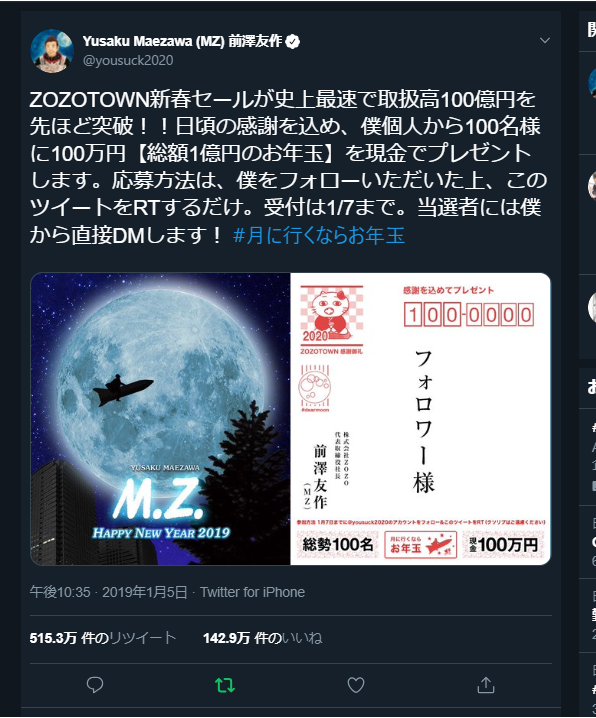
今回はリツイートだけでなく、この企画全体の影響を可視化したっかった、という気持ちもありました。
例えば、こういう偽物とか

便乗する人とか

便乗してイベントをする人とか(私達です)

もちろん、当選した人も。

なので、リツイートだけでなく、「#月に行くならお年玉」も対象に取得するのがいいんじゃないの? というのが最初の想定でした。
「query」をどう使う? Premium API の Search パラメータで使えるオペレーション一覧
その上で取得したいツイートは以下のように分類することができます。もちろん、これにハッシュタグのあり無しも加わるので、合計ざっくり8パターンといったところでしょう。

Premium Search API という名前の通り、この API は様々なQuery Operators を利用することが可能です。これを使えばなんとななるだろうと思って、いろいろと試してみたら
https://developer.twitter.com/en/docs/tweets/search/guides/premium-operators

まあ、リツイートも引用リツイートもハッシュタグが入ってるからいけるっしょ、という軽い気持ちで「#月へ行くならお年玉」で検索してみたら・・・以下のような結果に

※鍵付きアカウントは取得できない
そう、個人的に結構重要視していた「引用リツイート」の片方が取得できない!

で、どうする? 悩みどころ etc
というわけで、これをどうやって取得するか結構悩みました。
ちなみに、あるTwitterユーザーに対するリツイート・引用リツイートは取得できるが、 あるTwitterユーザーの特定のツイートに対する返信は取得できない、、、
さらに、、、引用リツイートの場合 Twitter の短縮URLが入力されるが これは検索対象外らしい、、
そもそも、一度リツイートだけ全部取得して、ハッシュタグ検索+リツイート除外ができればよかったが、それだと外野の声が聞こえない(偽物とかニュースとか)、、、
もしくは引用リツイート検索 + ハッシュタグ除外ができればよかったが、それは API の仕様上できない、、、
ユーザーのリツイートは検索+期間指定はできるが、対象のツイートだけではなくなってしまう、、、
じゃあ「#月に行くならお年玉」のハッシュタグが含まれていない引用ツイートも、ハッシュタグツイートも取得するならどうするか?
上にだらだら書いた通り、いろいろ悩んだ結果、私の今回の結論は

つまり

お金で殴る!(1000万ツイート取得すればいけただろうか。)
なので、今回は泣く泣く・・・・

Premium Search API の補足:ベースの検索は範囲指定:30日間の範囲で指定可能
ここからはちょっと Premium API の補足です。
Premium Search API は範囲指定が行えます。
例えば、UTC 2019/01/08 15:00(日本時間 2019/01/08 12:00)以降のツイートを取得したい場合は
toDate=201901101500
みたいな感じに指定するのですが、ちょっとクセがあります。
fromDateとtoDateで、その範囲の中で新しいツイートから順に取得してくるというもの。
ざっとまとめてみました。

Premium Search API の補足:ページネーションはさかのぼり方式
ページネーションは、レスポンスに含まれる「next=XXXXXX」というトークンを使って行います。
これも同じように、fromDate、toDate の範囲内で新しいものから順に取得してくるので要注意。
Standard Searchと若干勝手が違うので要注意。
Premium Search API の補足:取得できないもの
例えばなんですが、通常のTwitter Analytics だと以下のような分析ができると思うんですが

Twitter Search API経由で取得したデータでは以下のような要素が取得できません。
・フォロワー数の変化
・インプレッション
・クリック数
・見たユーザーの数
インプレッションなどは、リツイートのフォロワー数なども鑑みながら、擬似的に算出することができると思いますが、マーケティングやキャンペーン活動を行う上で、KPIを作る際には注意したいところです。
また、取得したデータにリツイートしたユーザーのフォロワー数なども含まれますが、そのデータは取得した時点のものです。
リツイートした時点のものではないので要注意。
そうして、ツイートを取得しました。
大したことはしていませんが、以下のプログラムでせっせと取得しています。
これで、こーんな感じのデータを取得しました。

ボトルネック③ どうやって Twitter の JSON データを構造化するの?
さて、とりあえず JSON は取得したわけですが、JSONのような非構造化データでは分析する時にうまくBIツールなどへ流し込むことができません。
表形式にうまく抽出する必要があります。

でも、Twitter のオブジェクトってかなり多様なフォーマットをしていまして、、、
おもに以下の4種類のパターンにわけられます。
Basic Tweet Format

Extended Tweets Format

Retweets Format

Retweets and Quote Tweets Format

これをすべて考慮して、構造化するのめんどくさい! ひとまずある程度フラット化して、DB(RDBなりNoSQLなり)に突っ込んで楽したい!
解決アプローチ
そこで、せっかくなら自社製品を利用してやろう! ということで、CData JSON Driver を利用することにしました。

CData JSON Driver は一定の件数のJSONファイルをスキャンして、スキーマを識別、それを勝手にリレーショナル化してくれるというなんとも便利な機能があります。
しかも複数ファイルの読み取りをサポートしているので、1フォルダに約8000ファイルあっても、全部かっさらってくれます。

こんな感じでリレーショナルにスキーマ検出ができました。

そして、こんな風にデータを取得できるようになりました!

もうちょっと詳しい CData JSON Driver の解説は以下からどうぞ。
ボトルネック④ どうやって DB にデータを流し込むの?
さて、分解できたのはいいですが、都度 JSON ファイルにアクセスする方式ではさすがにパフォーマンスが厳しいです。
とはいえ、テラバイトやペタバイト級のデータでも無いですし、1回データなのでストリーミング処理も要らなければ、構文解析などまで手を染めるつもりはなかったので、純粋にクラウドのRDBに投げて、BIツールで分析したいなーというところでもありました。

めんどくさいこと
もちろん、テーブルを作ってプログラムを書いて流し込んでもいいんですが
・Create Table を作るのがたるい。
・分割したリレーショナルテーブルだけ処理を書かないといけない。
・大量レコードなので、やり直ししやすいほうがいい。
データ投入アプローチ
そこでまた手前味噌ですが、CData Sync を活用しました。
自動データレプリケーション | CData Software Japan

CData で提供している各種ラインナップのデータソースをまるっとRDBやNoSQLにレプリケートしてしまうツールです。

これで、CData JSON Driver と CData Sync を組わせることで SON Driver で識別したフォーマットのまま、ノンプログラミングでさくっと Azure SQL にデータをレプリケートしてしまいました。
最終的なアーキテクチャはこんな感じです。

なお、CDataSync は自動的にテーブルとカラムも作成してくれて、型も判別してくれるので楽です。

データベースに入ってしまえばこっちのもので、

あとは SQL でデータを集計しながら、Power BIで接続してレポートを作成できた! という流れです。
こんな感じのレポートを Microsoft Power BI で作りました。できれば、この分析結果ベースで一つBlogを書きたいところですが、それはまた今度・・・。






終わりに
個人的にもはじめての取り組みでいろんな壁にぶちあたりながら取り組んだ企画でしたが
最終的にはこの Blog がきっかけで、Facebook上で SNS マーケーターの方と知り合うこともでき、一緒にイベントの開催までこぎつけることができました。
また、最初 Blog を書いたときには、まさかの思いもよらない出会いもありました。
イベントとしては、第1回が好評だったので、あと2回くらいはやりたいなと思っていますので、気になる方は是非Twitterなどをフォローしてもらえると嬉しいです。
最後に、様々な出会いとご支援に感謝!